Probabilistic models—a foundation of modern data analysis—rely on simplifying assumptions of complex real-life phenomena. Crucially, these methods operate on the assumption that the model is correct. Complex models are often necessary to accurately learn about sophisticated real-world phenomena, but even with careful model checking, some amount of model misspecification is inevitable. In some cases, this misspecification may lead to undesirable behavior, such as uninterpretable or even misleading results.
My research focuses on studying misspecification in probabilistic models with the goal of understanding when our model assumptions lead to desirable behaviors and when they lead to misleading and uninterpretable inferences. My goal is to develop and understand statistical machine learning models under misspecification and distribution shift and to study the impact on downstream tasks, such as decision making.
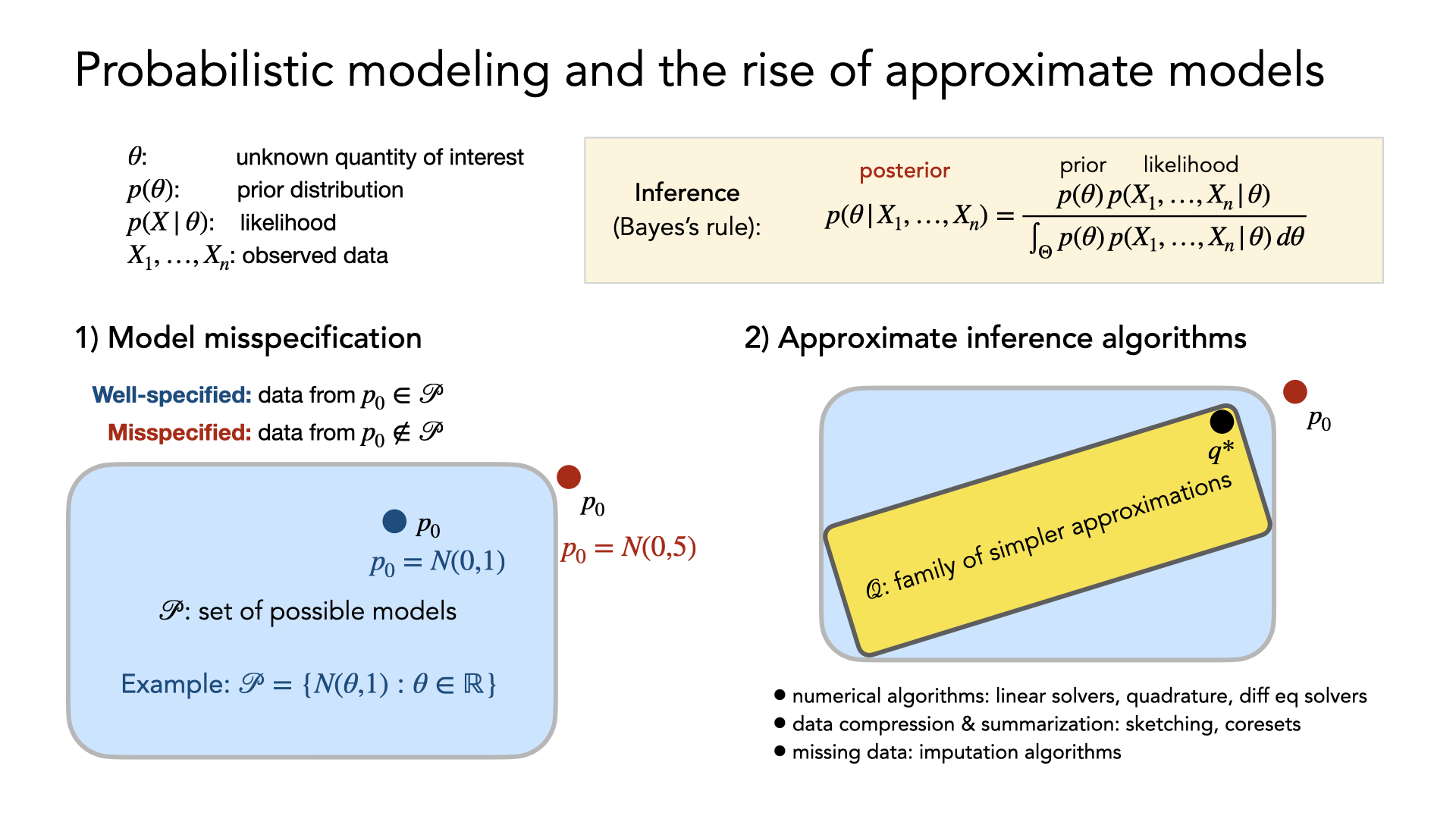
A few current reseach directions for understanding and developing more robust machine learning methods include studying:
- Model misspecification in latent variables, e.g., mixture models, and methods for Bayesian robustness
- Misspecification in network models including for sparsity and power laws
- Online changepoint detection for expensive models
- Multi-source meta-learning and transfer learning
- Flexible likelihood approximations via kernels in inverse reinforcement learning
See also our workshop at NeurIPS 2021: “Your Model is Wrong: Robustness and misspecification in probabilistic machine learning”.