The Julia Programming Language has finally released version 1.0!
I was still using version 0.6 when pretty much suddenly both v0.7 and v1.0 came out within a day apart (thanks JuliaCon).
— Diana Cai (@dianarycai) August 8, 2018</blockquote>
</div>
As a result, I didn’t get to actually try out a lot of the new features until now.
Here I’ll document the installation process and some first impressions.
On the Julia website is a nice blog post on new features of Julia 1.0.
They recommend installing v0.7 first, which contains deprecation warnings, fixing those warnings, then upgrading to 1.0.
Why is 1.0 so exciting? From the blog post linked above, it says
The single most significant new feature in Julia 1.0, of course, is a commitment to language API stability: code you write for Julia 1.0 will continue to work in Julia 1.1, 1.2, etc. The language is “fully baked.” The core language devs and community alike can focus on packages, tools, and new features built upon this solid foundation.
Installing Julia
I haven’t been using Homebrew to install Julia since v0.5, and so I decided to
go with that again this time. The first thing I did was download and install
Julia from the website, and then create the symlink:
Now typing in julia into the command prompt brings up the 1.0 REPL. The
new REPL now starts up noticeably faster than before.
I compared the startup time: for version 1.0, we have
~ $ time julia -e""
real 0m0.360s
user 0m0.114s
sys 0m0.153s
and for version 0.6, we have
~ $ time /Applications/Julia-0.6.app/Contents/Resources/julia/bin/julia -e""
real 0m0.829s
user 0m0.306s
sys 0m0.237s
Installing Packages in the REPL
Next up is installing packages that I need for work. The first thing I always do
is install IJulia, and so after trying Pkg.add("IJulia"), I was
immediately reminded that there is now a new package manager.
To access Pkg, the new package manager,
press the ] key in the REPL. Then we just type the package name at the
prompt, e.g.,
(v1.0) pkg> add IJulia
Multiple packages can be installed in each line by specifying add Pack1 Pack2
Pack3. Typing help will display a list of commands. To return to the julia> prompt, press backspace on an empty prompt or Ctrl+C.
Now IJulia is installed. After starting up jupyter notebook and confirming
that the v1.0.0 kernel was present, I then proceeded to install my usual packages:
Distributions, StatsBase - for basic probabilistic modeling and statistics
Seaborn (which installs all the Python dependencies) - plotting built on PyPlot (and PyCall to Matplotlib)
Optim - optimization package
Calculus, ForwardDiff - computing derivatives
DataFrames, CSV - for reading data, saving and loading experimental results
The installation process was quite fast for each package. Overall, I like the
simplicity of the interface for the new package manager.
While I was able to successfully install all of the packages above, I wasn’t able to
successful install a few packages that either hadn’t yet upgraded to v0.7 or had
some dependency that hadn’t yet upgraded.
Thus, if your work depends heavily on certain packages that have yet to be
updated, it may be worth sticking with v0.6 for a little bit longer.
Installing packages from Github
However, it’s worth checking the package online to see if you can directly download the latest
code from Github. E.g., if you go to the package’s Github page and see that
there have been indeed updates for v0.7, then try installing directly from
Github.
After trying to import a few packages (PyPlot and Seaborn), I found that they had import errors during precompilation
(e.g., ERROR: LoadError: Failed to precompile LaTeXStrings), which were
usually due to some issue with a dependency of that package. For example, for PyPlot, I found
that the package LaTeXStrings had indeed made fixes for 0.7, but this seemed to
not be in the latest release, and so I removed the package and added the code on
the master branch on Github:
(v1.0) pkg> add LaTeXStrings#master
This fixed the issue with both PyPlot and Seaborn immediately in that I could
now import the packages.
However, I wasn’t able to get the plot function to actually work initially.
After adding PyCall#master, I was able to get PyPlot and Seaborn
both working in both the REPL and Jupyter notebooks.
As in the old package manager, we can still install unregistered packages by
adding the URL directly, which is really nice for releasing your own research code for others to use.
Final Thoughts
While the Julia v1.0 upgrade was very exciting, because many packages that I
rely on aren’t yet 1.0-ready, I’m going to hold off on transitioning
my research work and code to v1.0, and stick with v0.6 for a little longer.
Supposedly the Julia developers will release a list of 1.0-ready packages soon.
From perusing the Julia channel, it seems like many packages are become almost
ready. I plan to check back again in a month or so to see if packages I rely on are
ready for use. Overall, I’m thrilled that v1.0 is finally released, and look forward to using it soon.
I’ll describe my current LaTeX setup – vim, skim, and latexmk.
I currently write notes and papers using LaTeX on a Mac, though in a previous life, my setup on Linux was very similar (i.e., s/macvim/gvim/g and s/skim/zathura/g).
I like being able to use my own customized text editor (with my favorite keyboard shortcuts) to edit a raw text file that I can then put under version control.
Though I describe things with respect to vim, most of this setup can also
achieved with some other text editor, e.g., emacs or sublime.
The basic setup
Text editor: vim
I use the text editor, vim. For writing documents, I often also like using macvim, which is
basically vim but with a few extra GUI features, such as scrolling and text
selection features.
PDF reader: Skim
For my pdf reader, I use the Skim app. The nice thing about Skim is that it will
autoupdate the pdf after you compile the tex and keep the document in the same
place. By contrast, Preview will refresh the document and reload it from the
beginning of the document, which is quite cumbersome if you’d just edited text on page 5.
Compilation: latexmk + vim keybindings
In vim, I have several keybindings set up in my .vimrc file.
Currently, I compile the .tex file using latexmk.
Files can be compiled to pdf with the command
latexmk -pdf[file]
In latexmk, you can also automatically recompile the tex when needed, but I prefer to manually compile the tex.
I have the following key bindings in vim:
control-T compiles the tex to pdf using latexmk
shift-T opens the pdf in Skim
shift-C cleans the directory
For instance, the compile keybinding above is done by adding the following line
to the .vimrc file
These types of key bindings can usually be setup with other text editors as well.
Putting it all together
When I’m writing a document, I’ll often have my text editor full screen on the
left and the Skim on the right with the pdf open. After making edits, I’ll press
control-T to compile and the pdf will auto-refresh in Skim.
Example of macvim next to Skim setup. Monitor recommended :)
Tools for writing LaTeX documents
There are a few other tools that I use for writing papers (or extensive notes on
work) that I’ll list below that save me a lot of time.
Plugins: snippets
In vim, I have several plugins I have in my .vimrc file. For writing papers, I
use ()[snippets] extensively. My most used command is typing begin <tab>, which
allows me to allows me to autocomplete the parts of LaTeX that I don’t want to
spend time typing but use often. For instance, in the TeX below, snippets means
I only have to type align* once.
And should I need to change align* to just align, I only have to
edit this in one of the parens instead of in both lines.
To use vim plugins (after installing), you just need to add the github page to your .vimrc file, e.g., for
Ultisnips, add the line
Plugin 'SirVer/ultisnips'
and execute :PluginInstall while in command mode in vim.
TeX skeleton
For writing quick notes, I have a TeX skeleton file that always loads when I
start a new vim document, i.e., when executing vim notes.tex in the
command line, a fully-functional tex skeleton with all the packages I normally use and font styles are
automatically loaded. E.g., a version of the following:
For longer documents, I use the subfiles package extensively.
This allows me to split a document into smaller files, which can then be
individually compiled into its own document. Subfiles inherit the packages, etc.,
that are defined in the main file in which the subfiles are inserted.
The advantage of using subfiles is that you
can just edit the subfile you’re currently focusing on, which is much faster
than compiling the entire document (especially one with many images and references).
This also helps with reducing the number of git conflicts one encounters when
collaborating on a document.
macros
I have a set of macros that I commonly use that are imported when I load a .tex
document. For writing papers, I’ll include a separate macros.tex file with all
of my macro definitions that I reuse often. Some example macros I’ve defined:
\reals for \mathbb{R}
\E for \mathbb{E}
\iid for \stackrel{\mathrm{iid}}{\sim}
\convas for \stackrel{\mathrm{a.s.}}{\longrightarrow}
Also super convenient if you’re defining a variable that is always bold if, for
instance, that variable is a vector.
commenting
My collaborators and I often have a commenting file we use to add various comments (in different colors too!) in the margins, in the text, or highlighting certain regions of the text.
An alternative is to use a LaTeX commenting package
and then define custom commands controlling how the comments appear in the text.
.vimrc
You can check out my .vimrc file on github to see how I set up keybindings, plugins, and
my .tex skeleton file.
In this post, we discuss the natural gradient, which is the direction of
steepest descent in a Riemannian manifold [1], and present the main result of
Raskutti and Mukherjee (2014) [2], which shows that the mirror descent algorithm is equivalent to natural
gradient descent in the dual Riemannian manifold.
Motivation
Steepest descent line search
Suppose we want to minimize some convex differentiable function
\(f: \Theta \rightarrow {\mathbb{R}}\) . A common approach is to do a line
search using the steepest descent algorithm
\(\begin{aligned}
\theta_{t+1} = \theta_t - \alpha_t \nabla f(\theta),\end{aligned}\)
where \(\alpha_t\) is the step-size and the direction we step in is the
gradient of the function.
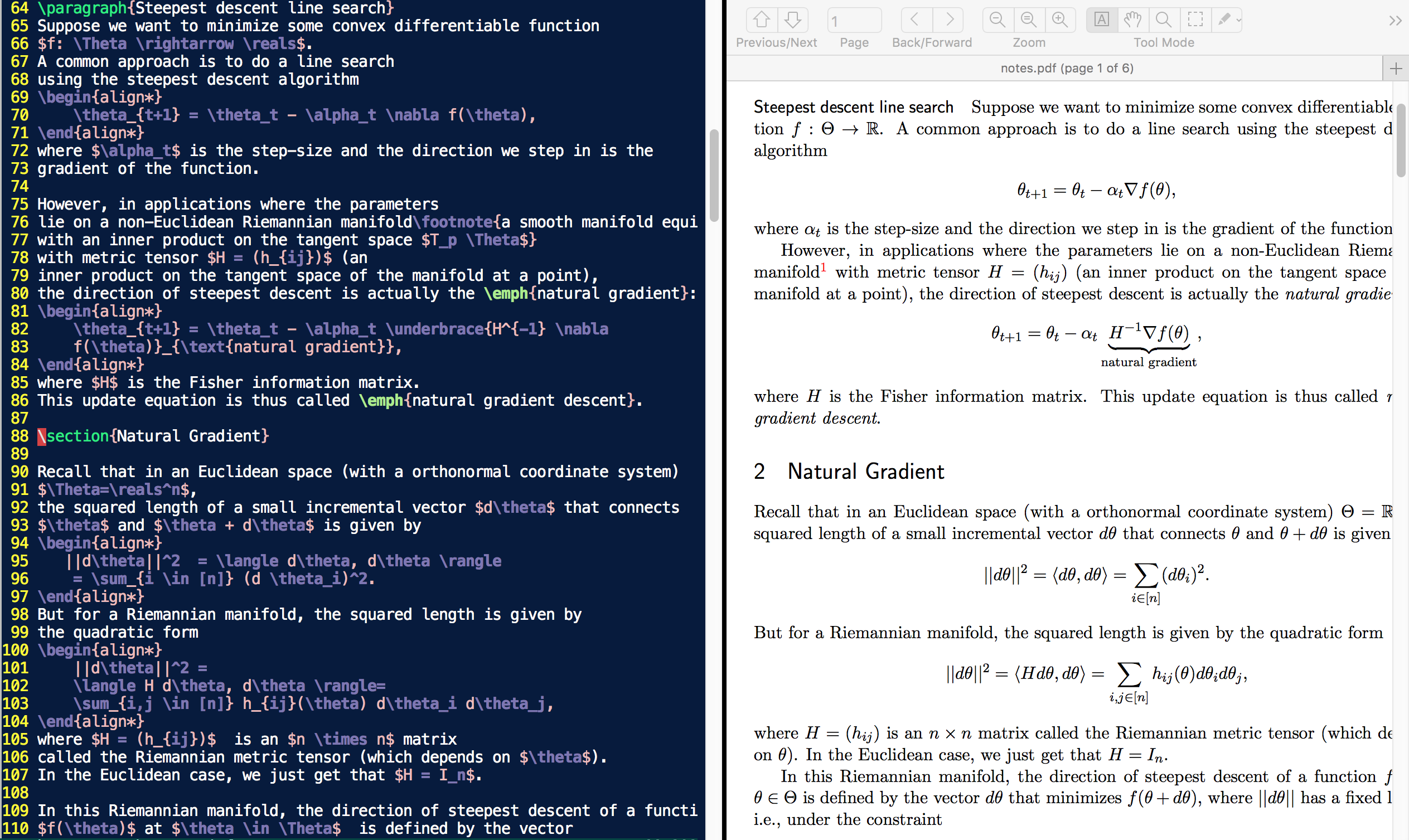
However, in applications where the parameters lie on a non-Euclidean
Riemannian manifold1 with metric tensor \(H = (h_{ij})\) (an inner
product on the tangent space of the manifold at a point), the direction
of steepest descent is actually the natural gradient:
where \(H\) is the Fisher information matrix for a statistical manifold. This update equation is called
natural gradient descent.
Natural Gradients
Recall that in an Euclidean space (with a orthonormal coordinate system)
\(\Theta={\mathbb{R}}^n\) , the squared length of a small incremental
vector \(d\theta\) that connects \(\theta\) and \(\theta + d\theta\) is given by
where \(H = (h_{ij})\) is an \(n \times n\) matrix called the Riemannian
metric tensor (which depends on \(\theta\).
In the Euclidean case, we just get that \(H = I_n\).
In this Riemannian manifold, the direction of steepest descent of a
function \(f(\theta)\) at \(\theta \in \Theta\) is defined by the vector
\(d\theta\) that minimizes \(f(\theta + d\theta)\), where \(||d\theta||\) has
a fixed length, i.e., under the constraint
Proof:
Write \(d\theta = \epsilon v\), i.e., we decompose the vector into its
magnitude \(\epsilon\) and direction \(v\), and search for the vector
\(v\) that decreases the value of the function the most.
\[\begin{aligned}
\nabla f(\theta) &= 2 \lambda H v \\
\implies
v &= \frac{1}{2\lambda} H^{-1} \nabla f(\theta),
\end{aligned}\]
which is the direction that causes the function’s value to decrease the
most. Lastly, plugging \(v\) above into the constraint \(v^\top H v = 1\),
we can solve for \(\lambda\).
Thus, the direction of steepest descent is \(H^{-1} \nabla f(\theta)\),
i.e., the natural gradient.
Lastly, note that in a Euclidean space, the metric tensor is just the
identity matrix, so we get back standard gradient descent.
Mirror descent and Bregman divergence
Mirror descent is a generalization of gradient descent that takes into
account non-Euclidean geometry. The mirror descent update equation is
we get back the standard gradient descent update2.
The proximity function \(\Psi\) is commonly chosen to be the Bregman divergence. Let
\(G: \Theta \rightarrow {\mathbb{R}}\) be a strictly convex,
twice-differentiable function, then the Bregman divergence
\(B_G: \Theta \times \Theta \rightarrow {\mathbb{R}}^+\) is:
Now, if \(G\) is a lower semi-continuous
function, then we have that \(G\) is the convex conjugate of \(H\). This
implies that \(G\) and \(H\) have a dual relationship. If \(G\) is strictly
convex and twice differentiable, so is \(H\). Let \(g = \nabla G\) and
\(h = \nabla H\). Then \(g = h^{-1}\).
Now let \(\mu = g(\theta) \in \Phi\) be the point at which the supremum
for the dual function is attained be the dual coordinate system to
\(\theta\). The dual Bregman divergence
\(B_H: \Phi \times \Phi \rightarrow {\mathbb{R}}^+\) induced by the
strictly convex differentiable function \(H\)
since the expression in the supremum is maximized when \(\theta = \mu\)
(so we plug this in for \(\theta\) to get the second line). Then we can
easily write the Bregman divergence induced by \(G,H\) as
Now that we have introduced what the Bregman divergence of an
exponential family looks like (with respect to the log partition
function \(G\) and its dual Bregman divergence with respect to \(H\), where
\(H\) is the conjugate of \(G\), we are ready to discuss the respective
primal and dual Riemannian manifolds induced by these divergences.
Primal Riemannian manifold: \((\Theta, \nabla^2 G)\), where
\(\nabla^2 G \succ 0\) (since \(G\) is strictly convex and
twice differentiable).
Dual Riemmanian manifold: \(B_H(\theta,\theta’)\) induces the
Riemannian manifold \((\Phi, \nabla^2 H)\), where
\(\Phi = {\mu: g(\theta) = \mu, \theta \in \Theta}\), i.e., the
image of \(\Theta\) under the continuous map \(g = \nabla G\).
Theorem (Raskutti and Mukherjee, 2014) [2]:
The mirror descent step with Bregman divergence defined by \(G\) applied
to the function \(f\) in the space \(\Theta\) is equivalent to the natural
gradient step along the dual Riemannian manifold \((\Phi, \nabla^2 H)\).
(Proof Sketch):
Step 1: Rewrite the mirror descent update in terms of the dual
Riemannian manifold coordinates \(\mu \in \Phi\):
The main result of [2] is that the mirror descent update with Bregman
divergence is equivalent to the natural gradient step along the dual
Riemannian manifold.
What does this mean? For natural gradient descent we know that
the natural gradient is the direction of steepest descent along a
Riemannian manifold, and
it is Fisher efficient for parameter estimation (achieves the CRLB,
i.e., the variance of any unbiased estimator is at least as high as
the inverse Fisher information),
but neither of these things are known for mirror descent.
The paper also outlines potential algorithmic benefits: natural gradient
descent is a second-order method, since it requires the computation of
an inverse Hessian, while the mirror descent algorithm is a first-order
method and only involves gradients.
References
Amari. Natural gradient works efficiently in learning. 1998
Raskutti and Mukherjee. The information geometry of mirror
descent. 2014.
Footnotes
a smooth manifold equipped with an inner product on the tangent
space \(T_p \Theta\) ↩
this can be seen by writing down the projected gradient descent update and rearranging terms ↩
aka Fenchel dual, Legendre transform. Also e.g. for a convex
optimization function, we can essentially write the dual problem
(i.e., the inf of the Lagrangian), as the negative conjugate
function plus linear functions of the Langrange multipliers. ↩
The so-called “curse of dimensionality” reflects the idea that many methods are more difficult in higher-dimensions.
This difficulty may be due a number of issues that become more complicated in
higher-dimensions: e.g., NP-hardness, sample complexity, or algorithmic efficiency.
Thus, for such problems, the data are often first transformed using some
dimensionality reduction technique before applying the method of choice.
In this post, we discuss a result in high-dimensional geometry regarding
how much one can reduce the dimension while still preserving \(\ell_2\) distances.
Johnson-Lindenstrauss Lemma
Given \(N\) points \(z_1,z_2,\ldots,z_N \in \mathbb{R}^d\),
we want to find \(N\) points \(u_1,\ldots,u_N \in \mathbb{R}^k\),
where \(k \ll d\), such that the distance between points is approximately preserved, i.e.,
for all \(i,j\),
\[
||z_i - z_j||_2 \leq ||u_i - u_j||_2 \leq (1+\epsilon) ||z_i-z_j||_2,
\]
where \(||z||_2 := \sqrt{\sum_l |z_{l}|^2}\) is the \(\ell_2\) norm.
Thus, we’d like to find some mapping \(f\), where \(u_i = f(z_i)\), that maps
the data to a much lower dimension while satisfying the above inequalities.
The Johnson-Lindenstrauss Lemma (JL lemma) tells us that we need dimension \(k = O\left(\frac{\log N}{\epsilon^2}\right)\),
and that the mapping \(f\) is a (random) linear mapping. The proof of this lemma
is essentially given by constructing \(u_i\) via a random projection, and then
showing that for all \(i,j\), the random variable \(||u_i - u_j||\) concentrates around its expectation.
This argument is an example of the probabilistic method, which is a nonconstructive method of
proving existence of entities with particular properties: if the probability of
getting an entity with the desired property is positive, then this entity must be
an element of the sample space and therefore exists.
Proof of the JL lemma
We can randomly choose \(k\) vectors \((x_n)_{n=1}^k\), where each \(x_n \in \mathbb{R}^d\), by
choosing each coordinate \(x_{nl}\) of the vector \(x_n\) randomly from the set
\[
\left\{\left(\frac{1+\epsilon}{k}\right)^{\frac{1}{2}},-\left(\frac{1+\epsilon}{k}\right)^{\frac{1}{2}}\right\}.
\]
Now consider the mapping from \(\mathbb{R}^d \rightarrow \mathbb{R}^k\) defined by the inner products of \(z \in \mathbb{R}^d\) with the \(k\)
random vectors:
\[z \mapsto (z^\top x_1, \ldots, z^\top x_k)\]
So, each vector \(u_i = (z_i^\top x_1,\ldots, z_i^\top x_k)\) is obtained via a
random projection. (Alternatively, we can think of the mapping as a random linear transformation
given by a random matrix \(A \in \mathbb{R}^{k \times d}\), where the \(k\) vectors form the rows of the matrix, and \(Az_i = u_i\).)
The goal is to show that there exists some \(u_1,\ldots,u_k\) that satisfies the
above inequalities.
Fixing \(i,j\), define \(u := u_i - u_j\) and \(z := z_i - z_j\), and \(Y_n := \left(\sum_{l=1}^d z_l x_{nl} \right)^2\).
Thus, we can write the squared \(\ell_2\) norm of \(u\) as
\(\begin{aligned}
||u||_2^2 = ||u_i - u_j||_2^2 &= \sum_{n=1}^k \left( \sum_{l=1}^d z_l x_{nl} \right)^2
= \sum_{n=1}^k Y_n
\end{aligned},\)
where \(x_{nl}\) refers to the \(l\)th component of the \(n\)th vector.
Now we consider the random variable \(Y_n\) in the sum. The expectation is
\[ \mathbb{E}(Y_n) = \frac{1+\epsilon}{k} ||z||_2^2. \]
So, the expectation of \(||u||_2^2\) is
It remains to show that \(||u||_2^2\) concentrates around its mean \(\mu\), which we can
do using a Chernoff bound. In particular, consider the two cases of
\(||u||_2^2 > (1 + \delta) \mu\) and \(||u||_2^2 < (1 - \delta) \mu\).
Via a Chernoff bound, the probability of at least one of these two “bad” events occurring is upper bounded by
\[
\Pr[\{ ||u||^2 > (1+\delta) \mu)\} \lor \{||u||^2 > (1-\delta) \mu \}] < 2\exp(-c \delta^2 k),
\]
for some \(c > 0\).
Recall that \(||u|| := ||u_i - u_j||\), and so there are \(\binom{N}{2}\) such random variables.
Now choosing \(\delta = \frac{\epsilon}{2}\), the probability that any of these random variables is outside of
\((1 \pm \frac{\epsilon}{2})\) of their expected value is bounded by
\[\binom{N}{2} \exp\left(-c \left(\frac{\epsilon}{2}\right)^2 k \right),\]
which follows from a union bound.
Choosing \(k > \frac{8(\log N + \log c)}{\epsilon^2}\) ensures that with all
\(\binom{N}{2}\) variables are within \((1 \pm \frac{\epsilon}{2})\) of their
expectations, i.e., \((1+\epsilon) ||z||_2^2\). Thus, rewriting this, we have that for all \(i,j\),
This post is a collection of references for Bayesian nonparametrics that I’ve found helpful or wish that I had known about earlier.
For many of these topics, some of the best references are lecture notes, tutorials, and lecture videos.
For general references, I’ve prioritized listing newer references with a more updated or comprehensive treatment of the topics.
Many references are missing, and so I’ll continue to update this over time.
Nonparametric Bayes: an introduction
These are references for people who have little to no exposure to the area, and
want to learn more. Tutorials and lecture videos offer a great way to get up to
speed on some of the more-established models, methods, and results.
This webpage lists a number of review articles and lecture videos that as an
introduction to the topic. The main focus is on Dirichlet processes, but a few
tutorials cover other topics: e.g., Indian buffet processes, fragmentation-coagulation processes.
An introduction to Dirichlet processes and the Chinese restaurant process,
and nonparametric mixture models. Also comes with R code for generating from and
sampling (inference) in these models.
This gives an overview of Dirichlet processes and Gaussian processes and places
these methods in the context of popular frequentist nonparametric estimation methods for, e.g., CDF and
density estimation, regression function estimation.
Theory and foundations
It turns out there’s a lot of theory and foundational topics.
A great introduction to foundations of Bayesian nonparametrics, and provides
many references for those who want a more in-depth understanding of topics.
E.g.: random measures, clustering and feature modeling, Gaussian processes,
exchangeability, posterior distributions.
Ghosal and van der Vaart. Fundamentals of Bayesian Nonparametric Inference.
Cambridge Series in Statistical and Probabilistic Mathematics, 2017.
contents
The most recent textbook on Bayesian nonparametrics, focusing on topics
such as random measures, consistency, contraction rates, and also covers
topics such as Gaussian processes, Dirichlet processes, beta processes.
Lecture notes with some similar topics as (and partly based on) the Ghosal and van der Vaart textbook, including a comprehensive treatment of posterior consistency.
Specific topics
Kingman. Poisson processes. Oxford Studies in Probability, 1993.
Everything you wanted to know about Poisson processes. (See Orbanz lecture
notes above for more references on even more topics on general point process theory.)
Having basic familiarity with measure-theoretic probability is fairly important for understanding many of the ideas in this section. Many of the introductory references aim to avoid measure
theory (especially for the discrete models), but even this is not always the case, so it is helpful to have as much exposure as possible.
Hoff. Measure and probability. Lecture notes. 2013. pdf
Gives an overview of the basics of measure-theoretic probability, which are often assumed in many of the above/below references.
Williams. Probability with martingales. Cambridge Mathematical Textbooks, 1991.
Cinlar. Probability and stochastics. Springer Graduate Texts in Mathematics. 2011.
Models and inference algorithms
There are too many papers on nonparametric Bayesian models and inference methods. Below, I’ll list a few “classic” ones, and continue to add more over time.
The above tutorials contain many more references.
Dirichlet processes: mixture models and admixtures
Dirichlet process mixture model
Neal. Markov Chain sampling methods for Dirichlet process mixture models.
Journal of Computational and Graphical Statistics, 2000.
pdf
Blei and Jordan. Variational inference for Dirichlet process mixtures.
Bayesian Analysis, 2006.
pdf
Hierarchical Dirichlet process
Teh, Jordan, Beal, Blei. Hierarchical Dirichlet processes.
Journal of the American Statistical Association, 2006.
pdf
Hoffman, Blei, Wang, Paisley. Stochastic variational inference.
Journal of Machine Learning Research, 2013.
pdf
Nested Dirichlet process & Chinese restaurant process
Rodriguez, Dunson, Gelfand. The Nested Dirichlet process.
Journal of the American Statistical Association, 2008.
pdf
Blei, Griffiths, Jordan. The nested Chinese restaurant process and Bayesian
nonparametric inference of topic hierarchies.
Journal of the ACM, 2010.
pdf
Antoniak. Mixture of Dirichlet processes with applications to Bayesian nonparametrics.
Annals of Statistics, 1974.
pdf
Additional inference methods
Ishwaran and James. Gibbs sampling methods for stick-breaking priors.
Journal of the American Statistical Association, 2001.
pdf
MacEachern. Estimating normal means with a conjugate style dirichlet process prior.
Communications in Statistics - Simulation and Computation, 1994.
pdf
Escobar and West. Bayesian density estimation and inference using mixtures.
Journal of the American Statististical Association, 1995.
pdf
Indian buffet processes and latent feature models
Griffiths and Ghahramani. The Indian buffet process: an introduction and review.
Journal of Machine Learning Research, 2011.
pdf
Thibaux and Jordan. Hierarchical beta processes and the Indian Buffet
process. AISTATS, 2007.
pdf
|
longer